Open source data community has been rapidly growing over the last 10 years. You can feel this by the emerge of projects like Apache Hadoop, Apache Spark and the likes. It is growing this fast that there is almost no chance of keeping up with its growth without constantly monitoring the related events, announcements and other changes. 10 years ago it was enough to know “just Oracle” or “just MySQL” to make a successful career in data. Now the things has greatly changed, and if you cannot answer questions like “what is the difference between MapReduce and Spark?” and “when would you prefer to use Flink over Storm?” at your job interview you are screwed.

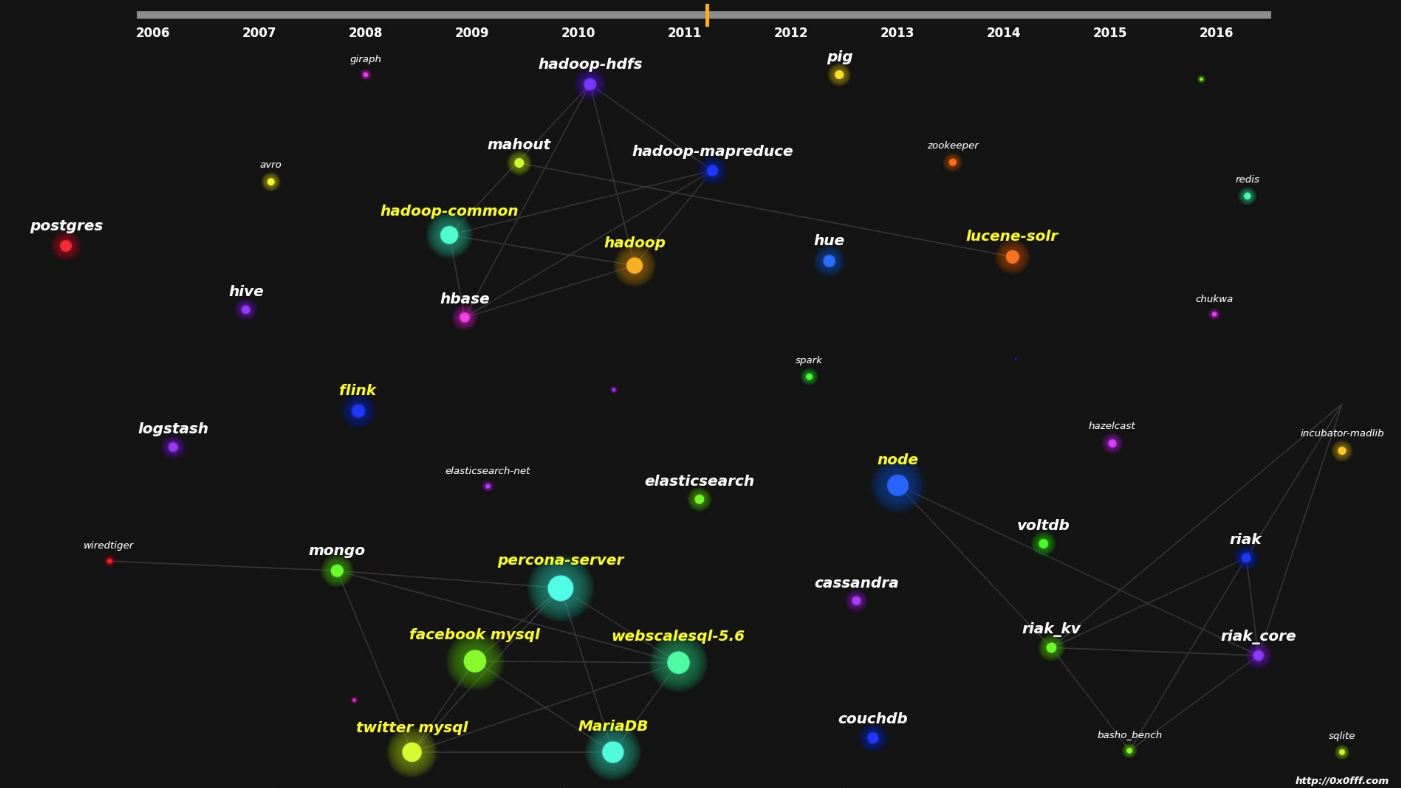
Github Data Community Graph Snapshot
Also, what would be the “next big thing” in data?
And where the community is moving to? You must have seen hundreds of blogs trying to describe their “vision” of the data over the next number of years. Most of them are sponsored by different vendors that try to replace prediction of community dynamics with shaping it, making you believe that “product X” is a next big thing for it to really become so. This is the marketing.
I’m not a big fan of marketing of any kind and I kindly believe that a good software will find its way even without this aggressive marketing. But thinking about the dynamics of open source data community, I was trying to find a trustful source of information, clean from the marketing of big enterprises. And I have found it: it is a github. Github stores source code for most of the open source data products. But it is not just sources, it is a complete story of changes for each of them, including information about the author of this change. What if I analyze this information to show what is happening in community? And here is what I ended up with:
Nodes of the graph represent open source data projects. Each node’s area is representing the number of unique contributors to the specific open source project over the last 10 weeks, prior to the moment of visualization shown on the timeline on top of the video. Edges represent relations between the projects. Relation between 2 open source projects exist if there is at least a single person that has contributed to both projects within the 10 week time range. Usually people are contributing to the related projects, for example people contributing to Apache Hadoop would likely also contribute to Apache HBase and Apache Hive. Colors of the nodes does not have any particular meaning, they are just selected from the colormap at random. All the animation is done in Python with matplotlib and lots of manual code to make it work the way I want.
In fact, there is a huge mutual relationship between many projects, this is why I also include the projects that are not directly related to “data”, but are also making impact on shaping the community of data. These project include Node.js, Docker, Kubernetes and the likes.
There is also a funny thing I have discovered analyzing all this data. There are only 8333 unique developers that are responsible for this whole progress! And luckily I’m one of them.
{kind=link}
Pingback: Open Source Data Community Visualization | Filling the gaps in Big Data
Hi, thank you for very nice visualization!
How did you pick the projects to be part of the open source data community firsthand? There are quite a few missing.
Are there any plans to keep this up or publish the scripts for to build such visualization?
Thanks again.
Picking projects was done in a following way – I has written down all the projects I could remember or know about their existence (around 70), then I run the first extraction from github using only these projects. After this extraction I processed recent commits of all the people who contributed to these 70 most popular projects to find other interesting projects, and picked of them the most popular ones.
I’ve already published the code I used – https://github.com/0x0FFF/githubgraph. It is quite dirty, but I didn’t have a plan to reuse in, at least in 1-2 years timeframe. If you’d like to add some other projects of exclude something – feel free to do so, keeping the reference to original author