The faster your data warehousing solution runs, the higher would be the business demand related to the speed of new data availability in their reports. Over the last time I’ve seen a number of attempts to build up a cool thing called “online DWH” – a data warehouse that is almost in sync with data sources and has its data marts and reports dynamically updated as new data flows into it. This is a very great and powerful thing, but unfortunately its implementation is not as straightforward as the business wants it to be.

Lets start with the problem that looks completely unrelated to the original subject. This is the general problem of OLTP and OLAP systems and their hardware designs.
When you plan OLTP system implementation how do you choose the hardware? This should be a pair or powerful servers, primary and standby, and a couple of good storages. Ideally storage solutions should be all-flash, but if you are limited in budget they should at least have a big flash storage layer and tiering supported out of the box.
When you plan OLAP system implementation you usually consider solutions like MPP databases or Hadoop. General approach for MPP hardware design is to use many small servers with direct attached storage and as many spindles as you can put there, even though the spindles themselves might be not the top tier, even 7.2k SATA drives would work well here. Similar approach is used for Hadoop cluster design – lots of commodity servers with DAS drives. The only difference is that MPP databases prefer RAID while Hadoop stands for JBOD.

Why do you think this difference in hardware design takes place? In other words, why cannot we use DAS server for OLTP database and storage solution for MPP database or Hadoop? The main difference is in the workload that these solutions should withstand. OLTP database should handle many parallel short-living transactions inserting/updating/deleting specific small sets of records in your tables. Usually to speed up this operation you introduce many indexes, which allows the database engine to faster identify the subset of records that should be selected/updated/deleted. For OLAP database, you are usually scanning through huge tables handling historical transactions or perform joins of big fact tables between each other and with different dimension tables. So for OLAP the main workload is data scanning, huge joins and huge aggregations.
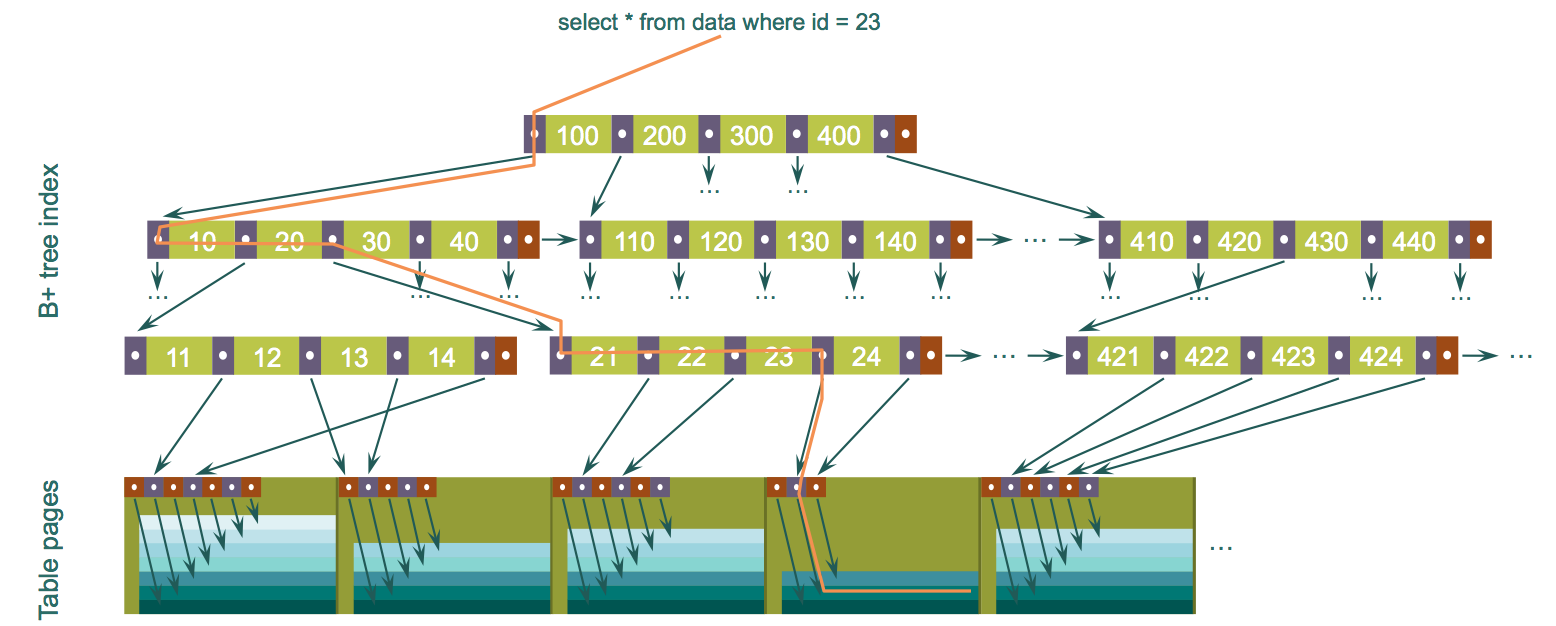
Here’s the typical path of the query retrieving single record from the table based on the index:

This is a simplified example, the real index tree would be deeper. What we can see is that even this specific sample query reads 4 separate blocks of data (3 for index and 1 for table). Reading distant blocks of information from HDD is called “random scans” as each operation of this kind consists of 2 separate ones – find the related block and read it. And random scan operations are extremely expensive for traditional HDDs.
As an example, let’s take a typical SAS 10k RPM HDD. For sequential read or write it would give you approximately 100MB/sec throughput. But when you would test 100% random reads and writes you would go to as low as 4-5MB/sec. It is 20 times slower than sequential scans.

OLTP systems tend to generate mostly random IO workload as their main task is to update specific rows in specific tables. How you can speed up random scans? First optimization is done by the database itself, it stores page cache in shared memory, so the more RAM your server has the better. Second optimization is on the storage side – if we get SSD instead of HDD, then we won’t have this huge difference between random and sequential IO. Third level is storage tiering – the more you access specific blocks of the data, the hotter they come and the higher probability that they would be moved to the SSD tier of your storage solution. If we go with OLTP system over DAS with spindles, we are at a big risk that our random IO would cause HDD saturation and our performance would be very low.
What about the OLAP systems? The main idea is to sequentially scan big tables and join them together. For joining full tables you cannot take advantage of the indexes (mathematically, index join works only for subsets of the tables) and the best option for joining is hash join, which should be done completely in memory. If there’s not enough memory, your query will spill part of the hash table to the HDD and scan one of the joining tables multiple times, but eventually all the operations would create only sequential IO workload.

Imagine the use of storage solution here. You’re joining 10TB fact table with a set of dimensions, how can the storage help you? You don’t need to move anything between tiers because you access all of the source tables only once and unlikely you would immediately run the same query for the second time. It will even get on your way for both MPP and Hadoop, because both these systems would have the storage as shared resource, which would put a huge pressure on the storage (thousands of parallel session) and would cause storage saturation and thus low performance. This is why storage solutions are not recommended for parallel systems.
{kind=link}
Knowing this, let’s return to the original topic, online data warehouse.
The business requirement here is to get the data from source systems faster and have more frequent updates of data marts and reports. How this can be achieved? You best friend would be CDC (Change Data Capture), that would allow you extract the data from source systems with almost no delay. This is very good for reducing the ETL pressure on the source systems. But here is what we will see on DWH side: the smaller batches of the data you are loading, the lower would be your data loading bandwidth. All of the DWH solutions are designed for batch loading of the data. To overcome this problem you would come out with the optimization – adding index to the tables being replicated with CDC. Using the index and micro-batches you are ready to keep up with the amount of data coming to your system. But what really happens here? You are using indexes, loading small number of records and making index lookups and single page data updates. And this is exactly the workload of OLTP system, not OLAP one. You are creating random IO workload on your DWH platform, which is optimized for OLAP workload and thus runs on DAS with traditional spindles.

Next step is to see your system at a bigger scale. You are loading changes from the source systems in micro batches and applying them online to your DWH. This means that you are literally replicating the workload of all the source systems on your DWH platform to have the actual data. But do you really think this is possible? DWH platforms are not designed for OLTP workload, and you are trying to make them run the same workload as the workload of all your OLTP systems together. This is why there is no such thing as online data warehouse.
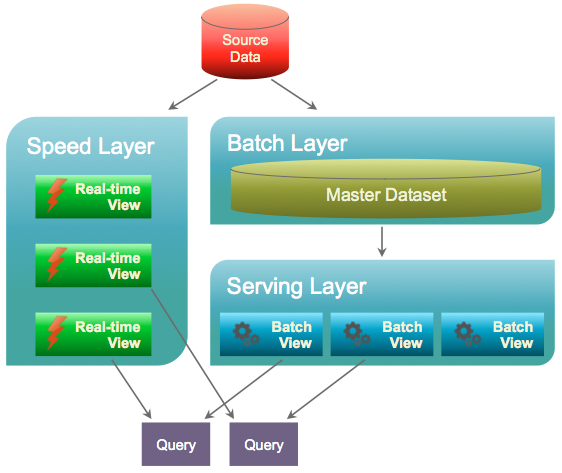
Online data warehouse cannot be built solely on MPP or Hadoop platform. You need to combine a number of approaches together. DWH is the system designed for daily data loads and daily ETL, and it should work only like this. There are a big number of online systems that would allow you to have real-time data ingestion and real-time report updates. For instance, you might consider something like Lambda architecture with real-time part running on Apache Storm or Apache Spark Streaming and batch part running on MPP or Hadoop. This would be a good solution and it would solve your problem with near real time data availability.

Twenty years ago you might think that to solve any data-related problem it is enough to use DBMS. Ten years ago you might start to doubt about it given the volume of data you are working with, and introduce MPP. Five years ago you already knew that there are a bunch of NoSQL solutions that could solve your specific data processing needs much easier than DBMS or MPP solution. And now you should finally come to understanding that many modern problems of data processing cannot be solved with traditional approaches that are 10 or even 20 years old, and you just cannot avoid using modern systems and modern architectures.
{kind=link}

“DWH platforms are not designed for OLTP workload, and you are trying to make them run the same workload as the workload of all your OLTP systems together. This is why there is no such thing as online data warehouse.”
1) Do you mean that, DWH does not have the CPU to reserve for frequent micro batches and pre-processing to make the data ready for consumption thru MPP analytical queries?
2) That is why, there is the Data Hub concept to fetch the data frequently from data sources (OLTP systems) and prepare it (ELT) for DWH for MPP analytics?
3) Why Kudu does not make sense to serve as “Online DWH” within Lambda Architecture? Meaning, data being transformed (ELT) by speed/batch layers can easily be merged for “Near Online DWH”?
Pingback: Greenplum vs PostgreSQL – Loitools.com
Pingback: [Fixed]-Greenplum vs PostgreSQL - TheCodersCamp
Hi, I have a photo of this tortoise in a frame can you confirm where you got the image from